Of confidence intervals and example in R Science 05.04.2014
Introduction
A confidence interval (CI) is an interval estimate of a population parameter and is used to indicate the reliability of an estimate and can be interpreted as the range of values that would contain the true population value 95% of the time if the survey were repeated on multiple samples.
The "90%" in the confidence interval listed above represents a level of certainty about our estimate. If we were to repeatedly make new estimates using exactly the same procedure (by drawing a new sample, conducting new interviews, calculating new estimates and new confidence intervals), the confidence intervals would contain the average of all the estimates 90% of the time. We have therefore produced a single estimate in a way that, if repeated indefinitely, would result in 90% of the confidence intervals formed containing the true value.
Confidence intervals are one way to represent how "good" an estimate is; the larger a 90% confidence interval for a particular estimate, the more caution is required when using the estimate. Confidence intervals are an important reminder of the limitations of the estimates.
Practical example
Say you were interested in the mean weight of 10-year-old girls living in the United States. Since it would have been impractical to weigh all the 10-year-old girls in the United States, you took a sample of 16 and found that the mean weight was 90 pounds. This sample mean of 90 is a point estimate of the population mean. A point estimate by itself is of limited usefulness because it does not reveal the uncertainty associated with the estimate; you do not have a good sense of how far this sample mean may be from the population mean. For example, can you be confident that the population mean is within 5 pounds of 90? You simply do not know.
Confidence intervals provide more information than point estimates. Confidence intervals for means are intervals constructed using a procedure (presented in the next section) that will contain the population mean a specified proportion of the time, typically either 95% or 99% of the time. These intervals are referred to as 95% and 99% confidence intervals respectively. An example of a 95% confidence interval is shown below:
72.85 < μ < 107.15
There is good reason to believe that the population mean lies between these two bounds of 72.85 and 107.15 since 95% of the time confidence intervals contain the true mean.
If repeated samples were taken and the 95% confidence interval computed for each sample, 95% of the intervals would contain the population mean. Naturally, 5% of the intervals would not contain the population mean.
Simulation in R
Let's simulate confidence interval in R and plot the result.
Say you have a sample from a population. Given that sample, you want to determine a confidence interval for the population’s mean.
We'll apply the t.test function to your sample x t.test(x). The output includes a confidence interval at the 95% confidence level. To see intervals at other levels, use the conf.level argument.
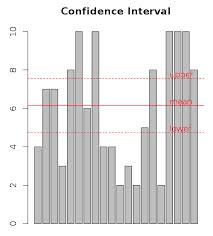
x = sample(10, 20, replace=T) # [1] 1 3 5 3 9 6 2 9 8 6 7 4 10 8 5 4 7 2 7 5 t.test(x) # One Sample t-test # data: x # t = 9.6021, df = 19, p-value = 1.008e-08 # alternative hypothesis: true mean is not equal to 0 # 95 percent confidence interval: # 4.340241 6.759759 # sample estimates: # mean of x # 5.55 lower = t.test(x)$conf.int[1] upper = t.test(x)$conf.int[2] amount = length(x) barplot(x, main="Confidence Interval") # plot mean abline(h=mean(x), lty=1, col="red") text(amount, mean(x), "mean", col="red", adj=c(0, -0.2)) # plot upper abline(h=upper, lty=2, col="red") text(amount, upper, "upper", col="red", adj=c(0, -0.2)) # plot lower abline(h=lower, lty=2, col="red") text(amount, lower, "lower", col="red", adj=c(0, -0.2))
Useful links
Quote
Categories
- Android
- AngularJS
- Databases
- Development
- Django
- iOS
- Java
- JavaScript
- LaTex
- Linux
- Meteor JS
- Python
- Science
Archive ↓
- September 2024
- December 2023
- November 2023
- October 2023
- March 2022
- February 2022
- January 2022
- July 2021
- June 2021
- May 2021
- April 2021
- August 2020
- July 2020
- May 2020
- April 2020
- March 2020
- February 2020
- January 2020
- December 2019
- November 2019
- October 2019
- September 2019
- August 2019
- July 2019
- February 2019
- January 2019
- December 2018
- November 2018
- August 2018
- July 2018
- June 2018
- May 2018
- April 2018
- March 2018
- February 2018
- January 2018
- December 2017
- November 2017
- October 2017
- September 2017
- August 2017
- July 2017
- June 2017
- May 2017
- April 2017
- March 2017
- February 2017
- January 2017
- December 2016
- November 2016
- October 2016
- September 2016
- August 2016
- July 2016
- June 2016
- May 2016
- April 2016
- March 2016
- February 2016
- January 2016
- December 2015
- November 2015
- October 2015
- September 2015
- August 2015
- July 2015
- June 2015
- February 2015
- January 2015
- December 2014
- November 2014
- October 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013